Video
Term Frequency (tf)
Term-Frequency(df) of term t for document d is the number of term frequency in the documents.
Inverse Document Frequency
Inverse Document Frequency(idf) is defined by following equation where N is the total documents having term t and df is the term frequncy for document d.
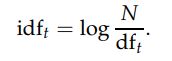
Term Frequency- Inverted Document Frequency
Term Frequency(df) and Inverted Document Frequency(idf) is combined to produce composite weight for each term and in each document using following equation.
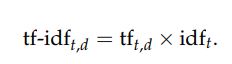
Stemming
Stemming usually refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes.
Similarity
To find similarity between search query and movies first I have generated word vector for each movie and using word vectors inverted term frequency was calculated. Now for new query we need to generate word vector of query and then calculate inverted term frequency. After that we need to calculate cosine similarity between inverted term frequency of query and of each movie. Then we will find top results whose cosine similarity is maximum.
Challenges
Efficiency
To implement function to calculate tf-idf for individual documents and terms is very resouce consuming process and to implement in efficient way is very important. I have tried different algorithms to improve time taken by functions. Initially it was taking around 2 minutes to calculate all the values and after imroving code it just take around 30 seconds.
Contribution
TF-IDF
Previously I was using scikit learn library than for better performance I have implemented all the calculation of tf-idf.
References