Video
Multinomial Naive Bayes Classifier
Naive Bayes classification works on probability of individual features within document. For movie classification movie description is data and each word or term in description is feature.
Formula
t1, t2, t3, … = Terms in data
P(Genre|[t1, t2, t3, …]) = P(Genre) * P(t1|Genre) * P(t2|Genre) * P(t3|Genre) * …
Genres
- Comedy
- Action
- Animation
- Romance
- Adventure
- Horror
Multilabel Classification
Movies can belongs to many classes such as an animation movie can be comedy as well. Multilabel classification is little bit triky. The model should return multiple genres. Following are the few techniques I have used.
1. Top Results
In top result technique it returns top n genres which has highest probability.
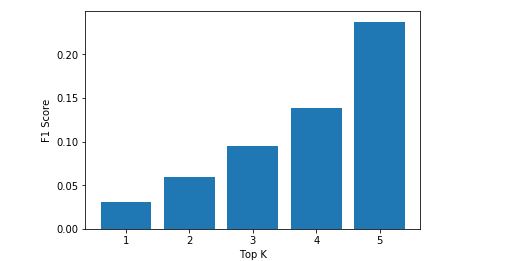
Pros: Easy and fast.
Cons: In most cases movies does not belongs to exactly n genres, it might belongs to less than or greater that n genres.
2. Threshold
In threshold it returns genres which has probability greater than threshold. We can find good threshold value by applying and evaluating different values.
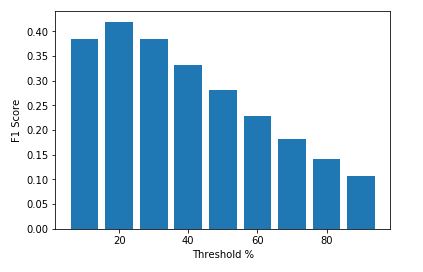
Cons: In naive bayes with text the range of probability changes with the number of terms in document. For example for one test case probability for genres might between 1.0e-1 to 1.0e-5 and for other it might be between 1.0e-10 to 1.0e-20 so there might be cases when it classify to all genres and ther might be case where it does not classify to any genre as well.
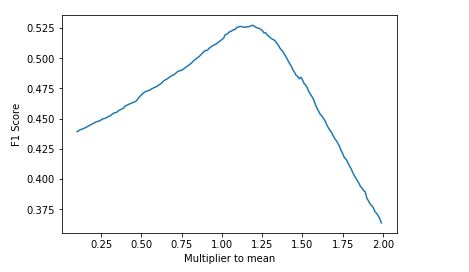
3. Mean
In this tehnique it returns the geners which has higher probability than other genres. For movie it first calculate probability using naive bayes theorem than it perform log and find mean of each genres, then it will return genres which has higher value than mean. In addition it has one variable which is muliplied by mean while comparing with each genre’s value and we can find good value by applying different values in this case we can use F1 Score and evaluate on validation data.
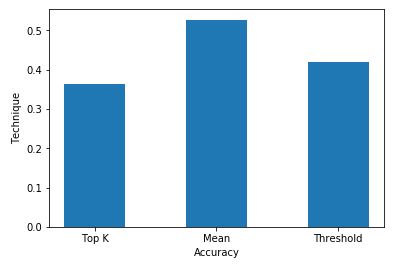
Comparison
Challenges
Accuracy
Improving accuracy was major challenge for this project. Following are the techniques used to improve accuracy.
- Stopwords
Stop words are the words which does not play significant role in solving problem such as “the”, “a”, “this”, etc. These words does not give any clue about genre and also these words repeats very much and that creates problem in classification.
Accuracy with stopwords: 0.5024773649566582
Accuracy without stopwords: 0.5178779592087157
- Lemmatization
Lemmatization is a process of finding root word for example “having” word is converted into “have”.
Accuracy after applying lemmatization: 0.527629565354579
Contribution
Multinomial Naive Bayes
Implemented multinomial naive bayes algorithm from scratch and tried to optimize as much as possible for quick response.
Multi Lable Classification
Tried different techniques to get multiple genres as a result such as top k, threshold, and created new method for retrieving multiple genres.
References